docker image的实现原理以及registry相关的一块知识
组长教学系列
May 4, 2019
2019
科技
part_one: 什么是文件挂载?
1. Unix里面的文件目录是目录树结构的形式,所有的文件目录都是基于硬盘disk逻辑抽象出来的。比如现在有一个的一个目录。

接1. 现在要把这些文件目录挂载到磁盘上面,在linux的文件系统里面,首先执行mount命令进行文件挂载,比如说将/(根目录)挂载到disk1里面,挂载完了以后,根目录下的进行创建操作或是写操作的时候,数据文件都会存储在disk1当中。
重点来了。比如说现在在data目录下创建一个文件a.txt, 这时候将/data挂载到disk2下面,这时候disk2中是看不到a.txt的。
part_two: 联合挂载
那么既然有要挂载以后再写才能看见的挂载,肯定有写完以后再挂载依旧能够看见之前已经写了的文件的挂载方式。docker layer就是属于这种。
part_three: docker 的layer和image的关系就有点像联合目录以及挂载点
也就是说,一个image代表的就是layer中的一个挂载点,而所有的layers就像是一个联合目录。
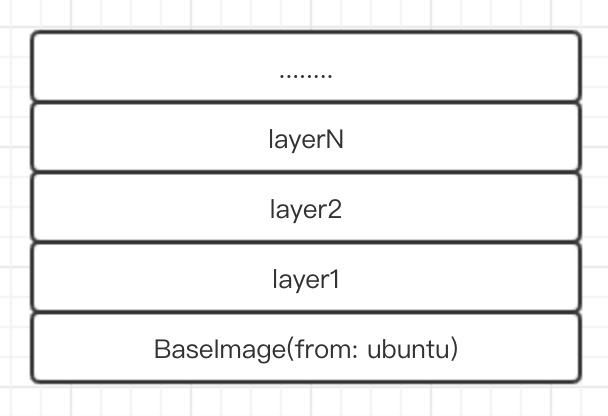
最先进行build的layer层就在栈底,同样最后build的layer层就在栈顶。比如说现在在layer1层进行touch a.txt和touch b.txt两个动作(要注意现在图中所示的所有layer层都是read-only)。layer2层进行touch a.txt。那么这个时候整个docker image build以后,使用这个image生成的实例以后,这个实例里面存在的是哪一层的a.txt。
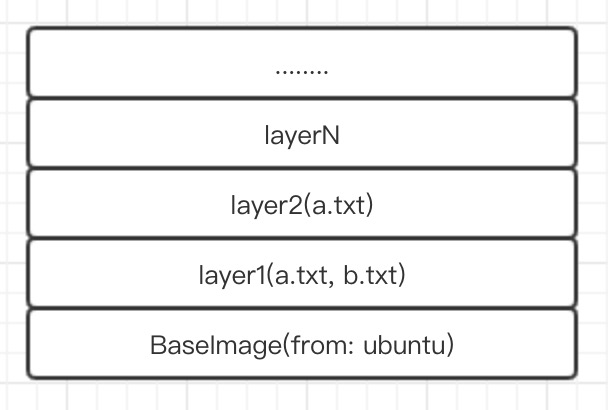
这就涉及到所谓的联合挂载了。也就是说当前的docker image 看得到之前的 docker image创建的全部的layers。现在请注意,接下来是重中之重,涉及image实现原理。课代表请记笔记。(我真的是个戏精)
part_three: docker image 实际上是怎么实现的
上个部分说到docker image是由很多个layer组成的,且这些layer是read-only的。每当生成一个新的实例以后,就会在栈顶增加一个writable-layer层。实际上是复制了一份read-only-layer中的数据到writable-layer中, 在container中修改的是这一层writable-layer中的数据。
好了,现在已经扯远了,回到问题上来,实际上一个docker image是由两部分组成的,分别是Manifest(layer_name list)和image_name(image_name: name:tag)
layer list中的每一个item,都是一个由hash(layer_content)=sha-256的这样一个hash值组成的。这样的hash有三个优点:1. 分布均匀;2. 碰撞少;3. 容易出现雪崩效应(所谓的雪崩效应输入值稍微改动一点点,hash值就会产生巨大的变化,这也是导致分布均匀的原因之一)。ps:Manifest也可以理解为是文件清单的意思。register(docker中的仓库)中其实存放了很多很多很多很多无序的layers。
part_four: 如何实现的layer不重复下载?
当我们build Dockerfile的时候, 首先会根据Dockerfile生成一张Manifest的表。里面存的是一堆的hash值。会根据这张表从栈顶开始查,查到栈底,这个hash值实际上可以理解为是digest, 通过和本地layer的sha-256值进行比对判断有没有必要再创建一个。
part_five: 回到一开始的问题,生成的contianer里面到底是那个layer的里的a.txt
再回到文件系统来说,启动一个容器的时候,可以看到容器里面是有一个完整的文件系统的,容器里面的所有文件都来自构成镜像的层。每个层里面都有文件。Docker通过aufs的技术,把所有的层都挂载到了同一个目录上(所以现在知道,所谓digest其实就是,把所有layer里面的文件打包压缩求hash)。 也就是这时候container会从栈顶往下开始找文件,走到layer2的时候找到了a.txt, 这时候就不会用到layer3中的a.txt, 而是加载b.txt。所以说container里面的其实是a,txt文件。